
The Best AIOPS Platform for Accelerated Business Outcomes with ZIFTM
The Best AIOPS Platform for Accelerated Business Outcomes with ZIFTM
ZIFTM Documents
Navigate to App settings Menu and click on the Tools Integration tab menu in ZIF. This will bring up the User Interface, which at this point is a blank canvas for orchestrating a new integration to initiate dataflow: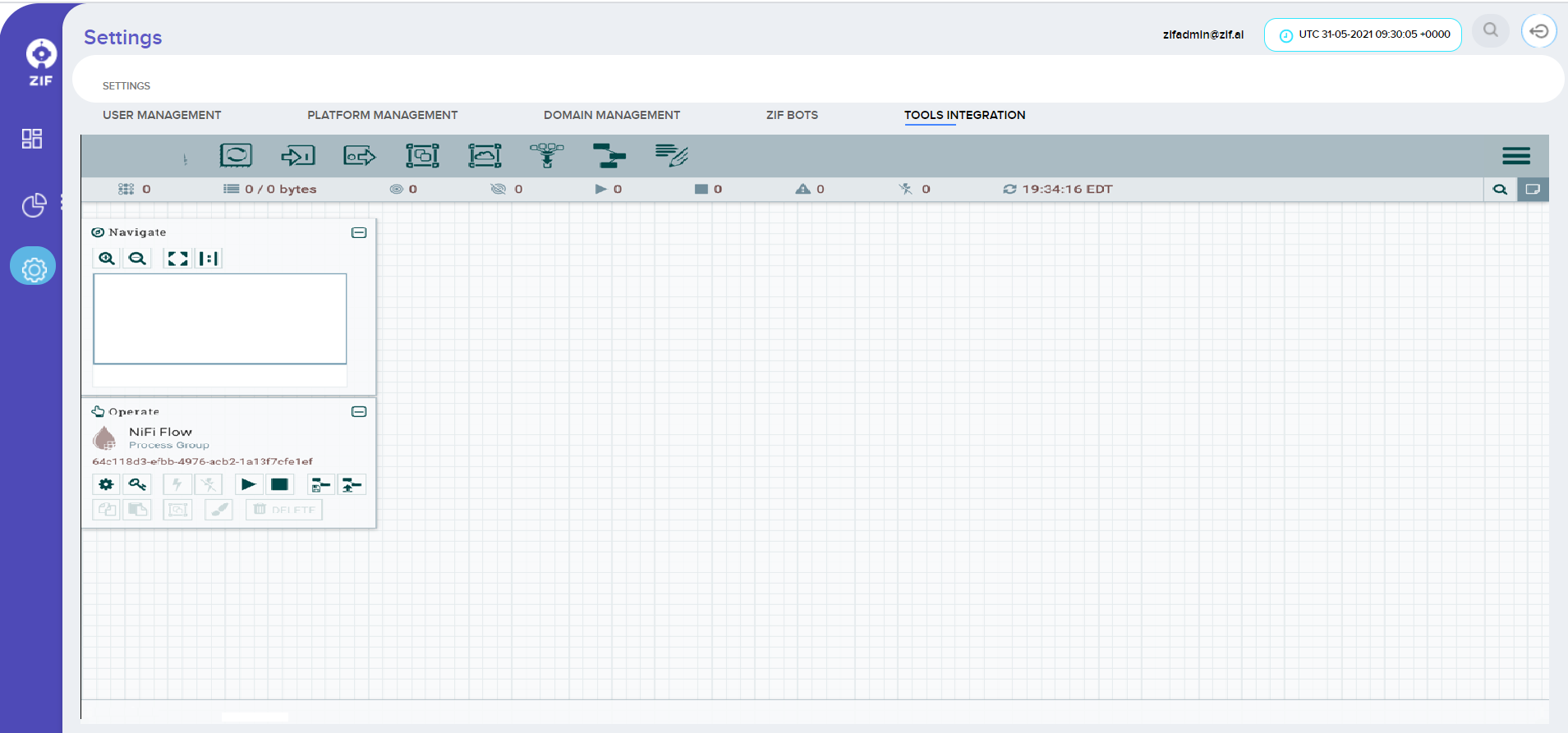
The UI has multiple tools to create and manage your first dataflow: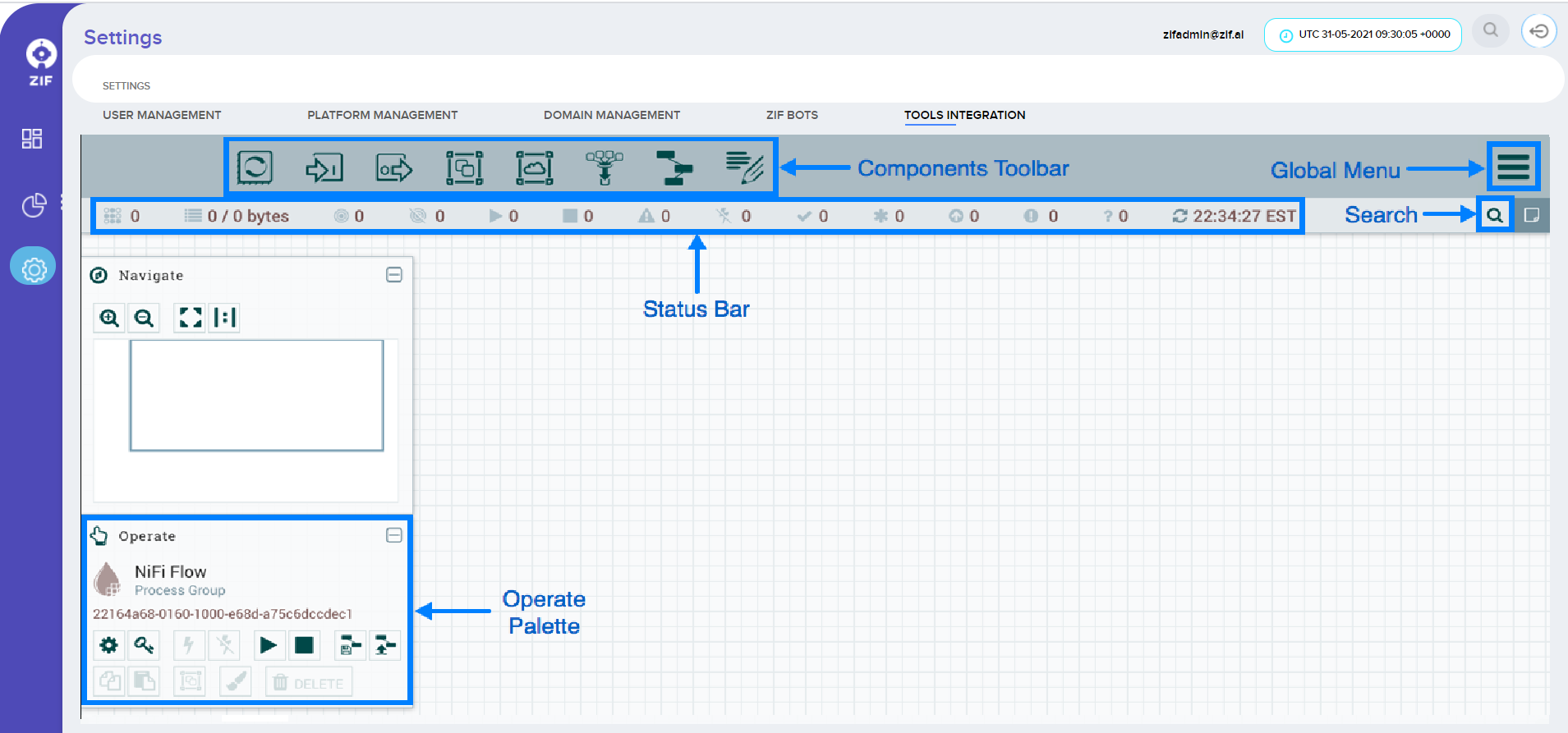
The Global Menu contains the following options: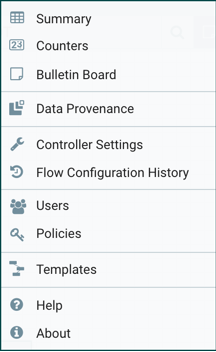
The below steps will guide how to integrate a new tool into ZIF. In the below, sample data ingestion from a local data disk to ZIF has been explained. To reuse integration templates already available in ZIF click here.
Begin creating data flow by adding a Processor to the canvas. To do this, drag the Processor icon (![]() ) from the top-left of the screen into the middle of the canvas (the graph paper-like background) and drop it there. This will give a dialog that allows us to choose which Processor we want to add:
) from the top-left of the screen into the middle of the canvas (the graph paper-like background) and drop it there. This will give a dialog that allows us to choose which Processor we want to add:
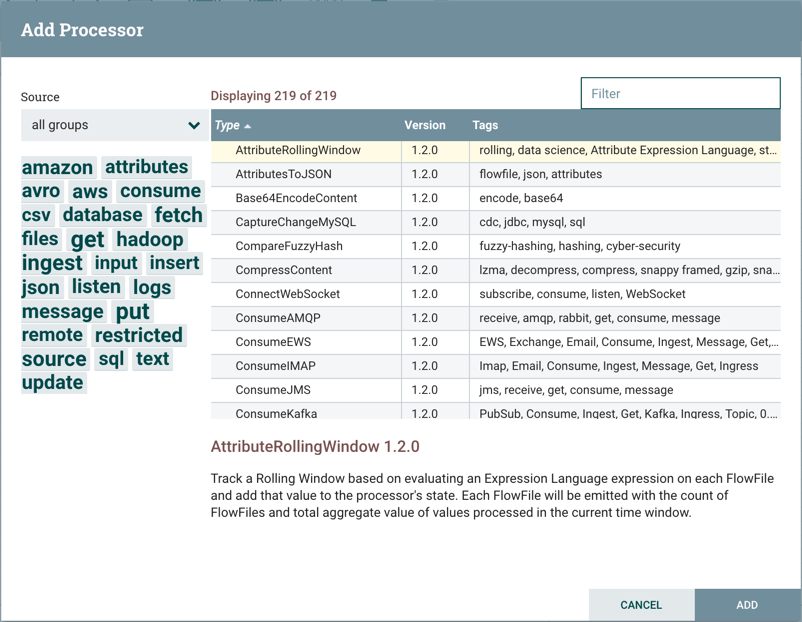
There are quite a few options to choose from. To start with, let’s say that we just want to bring in files from our local disk into Universal Connector. When a developer creates a Processor, the developer can assign “tags” to that Processor. These can be thought of as keywords. We can filter by these tags or by Processor name by typing into the Filter box in the top-right corner of the dialog. Type in the keywords that you would think of when wanting to ingest files from a local disk. Typing in the keyword “file”, for instance, will provide us a few different Processors that deal with files. Filtering by the term “local” will narrow down the list pretty quickly, as well. If we select a Processor from the list, we will see a brief description of the Processor near the bottom of the dialog. This should tell us exactly what the Processor does. The description of the GetFile Processor tells us that it pulls data from our local disk into Universal Connector and then removes the local file. We can then double-click the Processor type or select it and choose the Add button. The Processor will be added to the canvas in the location that it was dropped.
Now that we have added the GetFile Processor, we can configure it by right-clicking on the Processor and choosing the Configure menu item. The provided dialog allows us to configure many different options, but we will focus on the Properties tab for this integration. Once the Properties tab has been selected, we are given a list of several different properties that can be configured for the Processor. The available properties depend on the type of Processor and are generally different for each type. Properties that are in bold are required properties. The Processor cannot be started until all required properties have been configured. The most important property to configure for GetFile is the directory from which to pick up files. If we set the directory name to ./data-in, this will cause the Processor to start picking up any data in the data-in subdirectory of the Universal Connector Home directory. We can choose to configure several different Properties for this Processor. If unsure what a particular Property does, we can hover over the Help icon (![]() ) next to the Property Name with the mouse to read a description of the property. Additionally, the tooltip that is displayed when hovering over the Help icon will provide the default value for that property, if one exists, information about whether or not the property supports the Expression Language, and previously configured values for that property.
) next to the Property Name with the mouse to read a description of the property. Additionally, the tooltip that is displayed when hovering over the Help icon will provide the default value for that property, if one exists, information about whether or not the property supports the Expression Language, and previously configured values for that property.
In order for this property to be valid, create a directory named data-in in the Universal Connector home directory and then click the Ok button to close the dialog.
Each Processor has a set of defined “Relationships” that it can send data to. When a Processor finishes handling a FlowFile, it transfers it to one of these Relationships. This allows a user to configure how to handle FlowFiles based on the result of Processing. For example, many Processors define two Relationships: success and failure. Users are then able to configure data to be routed through the flow one way if the Processor can successfully process the data and route the data through the flow in a completely different manner if the Processor cannot process the data for some reason. Or, depending on the use case, it may simply route both relationships to the same route through the flow.
Now that we have added and configured our GetFile processor and applied the configuration, we can see in the top-left corner of the Processor an Alert icon (![]() ) signaling that the Processor is not in a valid state. Hovering over this icon, we can see that the
) signaling that the Processor is not in a valid state. Hovering over this icon, we can see that the success relationship has not been defined. This simply means that we have not told Universal Connector what to do with the data that the Processor transfers to the success Relationship.
In order to address this, let’s add another Processor that we can connect the GetFile Processor to, by following the same steps above. This time, however, we will simply log the attributes that exist for the FlowFile. To do this, we will add a LogAttributes Processor.
We can now send the output of the GetFile Processor to the LogAttribute Processor. Hover over the GetFile Processor with the mouse and a Connection Icon (![]() ) will appear over the middle of the Processor. We can drag this icon from the GetFile Processor to the LogAttribute Processor. This gives us a dialog to choose which Relationships we want to include for this connection. Because GetFile has only a single Relationship,
) will appear over the middle of the Processor. We can drag this icon from the GetFile Processor to the LogAttribute Processor. This gives us a dialog to choose which Relationships we want to include for this connection. Because GetFile has only a single Relationship, success, it is automatically selected for us.
Clicking on the Settings tab provides a handful of options for configuring how this Connection should behave:
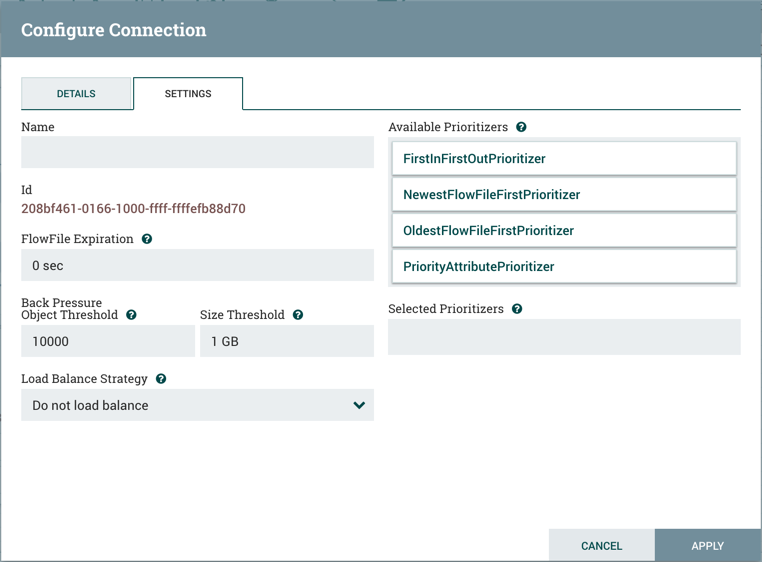
Connection name can be defined if needed. Otherwise, the Connection name will be based on the selected Relationships. We can also set an expiration for the data. By default, it is set to “0 sec” which indicates that the data should not expire. However, we can change the value so that when data in this Connection reaches a certain age, it will automatically be deleted (and a corresponding EXPIRE Provenance event will be created).
The backpressure thresholds allow us to specify how full the queue is allowed to become before the source Processor is no longer scheduled to run. This allows us to handle cases where one Processor is capable of producing data faster than the next Processor is capable of consuming that data. If the backpressure is configured for each Connection along the way, the Processor that is bringing data into the system will eventually experience the backpressure and stop bringing in new data so that our system has the ability to recover.
Finally, we have the Prioritizers on the right-hand side. This allows us to control how the data in this queue is ordered. We can drag Prioritizers from the “Available prioritizers” list to the “Selected prioritizers” list in order to activate the prioritizer. If multiple prioritizers are activated, they will be evaluated such that the Prioritizer listed first will be evaluated first and if two FlowFiles are determined to be equal according to that Prioritizer, the second Prioritizer will be used.
Simply click Add to add the Connection to our graph. We should now see that the Alert icon has changed to a Stopped icon (![]() ). The LogAttribute Processor, however, is now invalid because its
). The LogAttribute Processor, however, is now invalid because its success Relationship has not been connected to anything. Let’s address this by signaling that data that is routed to success by LogAttribute should be “Auto Terminated,” meaning that Universal Connector should consider the FlowFile’s processing complete and “drop” the data. To do this, we configure the LogAttribute Processor. On the Settings tab, in the right-hand side we can check the box next to the success Relationship to Auto Terminate the data. Clicking OK will close the dialog and show that both Processors are now stopped.
At this point, we have two Processors on our graph, but nothing is happening. In order to start the Processors, we can click on each one individually and then right-click and choose the Start menu item. Alternatively, we can select the first Processor, and then hold the Shift key while selecting the other Processor in order to select both. Then, we can right-click and choose the Start menu item. As an alternative to using the context menu, we can select the Processors and then click the Start icon in the Operate palette.
Once started, the icon in the top-left corner of the Processors will change from a stopped icon to a running icon. We can then stop the Processors by using the Stop icon in the Operate palette or the Stop menu item.
Once a Processor has started, we are not able to configure it anymore. Instead, when we right-click on the Processor, we are given the option to view its current configuration. In order to configure a Processor, we must first stop the Processor and wait for any tasks that may be executing to finish. The number of tasks currently executing is shown near the top-right corner of the Processor, but nothing is shown there if there are currently no tasks.
With each Processor having the ability to expose multiple different Properties and Relationships, it can be challenging to remember how all of the different pieces work for each Processor. To address this, you are able to right-click on a Processor and choose the Usage menu item. This will provide you with the Processor’s usage information, such as a description of the Processor, the different Relationships that are available, when the different Relationships are used, Properties that are exposed by the Processor and their documentation, as well as which FlowFile Attributes (if any) are expected on incoming FlowFiles and which Attributes (if any) are added to outgoing FlowFiles.
The toolbar that provides users the ability to drag and drop Processors onto the graph includes several other components that can be used to build a data flow. These components include Input and Output Ports, Funnels, Process Groups, and Remote Process Groups, which can be tried for various types of integration.
Fill in your details, our sales team will get in touch to schedule the demo.
