
Kappa (κ) Architecture – Streaming at Scale
We are in the era of Stream processing-as-a-service and for any data-driven organization, Stream-based computing has becoming the norm. In the last three parts https://bit.ly/2WgnILP, https://bit.ly/3a6ij2k, https://bit.ly/3gICm88, I had explored Lambda Architecture and its variants. In this article let’s discover Streaming in the big data. ‘Real-time analytics’, ‘Real-time data’ and ‘Streaming data’ has become mandatory in any big data platform. The aspiration to extend data analysis (predictive, descriptive, or otherwise) to streaming event data has been common across every enterprise and there is a growing interest to find real-time big data architectures. Kappa (K) Architecture is one that deals with streaming. Let’s see why Real-Time Analytics matter more than ever and mandates data streaming and how streaming architecture like Kappa works. Is Kappa an alternative to lambda?
“You and I are streaming data engines.” – Jeff Hawkins

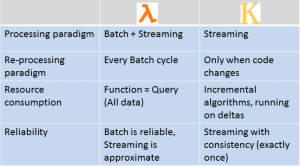
Lambda architecture fits very well in many real-time use cases, mainly in re-computing algorithms. At the same time, Lambda Architecture has the inherent development and operational complexities like all the algorithms must be implemented twice, once in the cold path, the batch layer, and another execution in the hot path or the real-time layer. Apart from this dual execution path, the Lambda Architecture has the inevitable issue of debugging. Because operating two distributed multi-node services is more complex than operating one.
Given the obvious discrepancies of Lambda Architecture, Jay Kreps, CEO of Confluent, co-creator of Apache Kafka started the discussion on the need for new architecture paradigm which uses less code resource and could perform well in certain enterprise scenarios. This gave rise to Kappa (K) Architecture. The real need Kappa Architecture isn’t about efficiency at all, but rather about allowing people to develop, test, debug, and operate their systems on top of a single processing framework. In fact, Kappa is not taken as competitor to LA on the contrary it is seen as an alternative.
Modern business requirements necessitate a paradigm shift from traditional approach of batch processing to real-time data streams. Data-centric organizations mandate the Stream first approach. Real-time data streaming or Stream first approach means at the very moment. So real-time analytics, either On-demand real-time analytics or Continuous real-time analytics, is the capability to process data right at the moment it arrives in the system. There is no possibility of batch processing of data. Not to mention, it enhances the ability to make better decision making and performing meaningful action on a timely basis. At the right place and at the right time, real-time analytics combines and analyzes data. Thus, it generates value from disparate data.
Typically, most of the streaming architectures will have the following 3 components:
Kappa (K) Architecture is one of the new software architecture patterns for the new Data era. It’s mainly used for processing streaming data. Kappa architecture gets the name Kappa from the Greek letter (K) and is attributed to Jay Kreps for introducing this architecture.
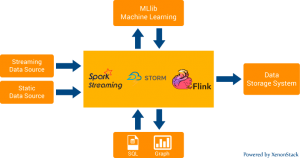
The main idea behind the Kappa Architecture is that both the real-time and batch processing can be carried out, especially for analytics, with a single technology stack. The data from IoT, streaming, and static/batch sources or near real-time sources like change data capture is ingested into messaging/ pub-sub platforms like Apache Kafka.
An append-only immutable log store is used in the Kappa Architecture as the canonical store. Following are the pub/sub or message buses or log databases that can be used for ingestion:

Distributed Stream processing engines like Apache Spark, Apache Flink, etc. will read the data from the streaming platform and transform it into an analyzable format, and then store it into an analytics database in the serving layer. Following are some of the distributed streaming computation systems
In short, any query in the Kappa Architecture is defined by the following functional equation.
The equation means that all the queries can be catered by applying Kappa function to the live streams of data at the speed layer. It also signifies that the stream processing occurs on the speed layer in Kappa architecture.
Pros
Cons
Absence of batch layer might result in errors during data processing or while updating the database that requires having an exception manager to reprocess the data or reconciliation.
On finding the right architecture for any data driven organizations, a lot of considerations were taken in. Like most successful analytics project, which involves streaming first approach, the key is to start small in scope with well-defined deliverables, then iterate. The reason for considering distributed systems architecture (Generic Lambda or unified Lambda or Kappa) is due to minimized time to value.

“ Bargunan is a Big Data Engineer and a programming enthusiast. His passion is to share his knowledge by writing his experiences about them. He believes “Gaining knowledge is the first step to wisdom and sharing it is the first step to humanity.“

We are proud to stay that ZIFTM is currently the only AIOps platform in the market to have a native mobile version! Look for ZIFTM AIOps on the App Store and Google Play Store.

Please complete the form details and a customer success representative will reach out to you shortly to schedule the demo. Thanks for your interest in ZIF!
