
Machine Learning: Building Clustering Algorithms
Clustering is a widely-used Machine Learning (ML) technique. Clustering is an Unsupervised ML algorithm that is built to learn patterns from input data without any training, besides being able of processing data with high dimensions. This makes clustering the method of choice to solve a wide range and variety of ML problems.
Since clustering is widely used, for Data Scientists and ML Engineer’s it is critical to understand how to practically build clustering algorithms even though many of us have a high-level understanding of clustering. Let us understand the approach to build a clustering algorithm from scratch.
Clustering is finding groups of objects (data) such that objects in the same group will be similar (related) to one another and different from (unrelated to) objects in other groups.
Clustering works on the concept of Similarity/Dissimilarity between data points. The higher similarity between data points, the more likely these data points will belong to the same cluster and higher the dissimilarity between data points, the more likely these data points will be kept out of the same cluster.
Similarity is the numerical measure of how alike two data objects are. Similarity will be higher when objects are more alike. Dissimilarity is the numerical measure of how different two data objects. Dissimilarity is lower when objects are more alike.
We create a ‘Dissimilarity Matrix’ (also called Distance Matrix) as an input to a clustering algorithm, where the dissimilarity matrix gives algorithm the notion of dissimilarity between objects. We build a dissimilarity matrix for each attribute of data considered for clustering and then combine the dissimilarity matrix for each data attribute to form an overall dissimilarity matrix. The dissimilarity matrix is an NxN square matrix where N is the number of data points considered for clustering and each element of the NxN square matrix gives dissimilarity between two objects.
Building a clustering algorithm involve the following:
There are different approaches to build a dissimilarity matrix, here we consider building a dissimilarity matrix containing the distance (called Distance Matrix) between data objects (another alternative approach is to feed in coordinate points and let the algorithm compute distance). Let us consider a group of N data objects to be clustered based on three data attributes of each data object. The steps for building a Distance matrix are:
Build a Distance matrix for individual data attributes. Here we build three individual distance matrices (one for each attribute) containing distance between data objects calculated for each attribute. The data is always scaled between [0,1] using one of the standard normalization methods such as Min-Max Scalar. Here is how the distance matrix for an attribute looks like.
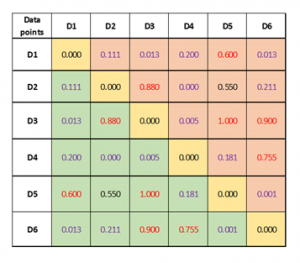
Build Complete Distance matrix. Here we build a complete distance matrix combining distance matrix of individual attributes forming the input for clustering algorithm.
Complete distance matrix = (element-wise sum of individual attribute level matrix)/3;
Generalized Complete distance matrix = (element-wise sum of individual attribute level matrix)/M, where M is the number of attribute level matrix formed.
Before the selection of a clustering algorithm, the following considerations need to be evaluated to identify the right clustering algorithms for the given problem.
There are broadly two applications of clustering.
As an ML tool to get insight into data. Like building Recommendation Systems or Customer segmentation by clustering like-minded users or similar products, Social network analysis, Biological data analysis like Gene/Protein sequence analysis, etc.
As a pre-processing or intermediate step for other classes of algorithms. Like some Pattern-mining algorithms use clustering to group patterns mined and select most representative patterns instead of selecting entire patterns mined.
Building ML algorithm is teamwork with a team consisting of SMEs, users, data scientists, and ML engineers, each playing their part for success. The article gives steps to build a clustering algorithm, this can be used as reference material while attempting to build your algorithm.

“Gireesh is a part of the projects run in collaboration with IIT Madras for developing AI solutions and algorithms. His interest includes Data Science, Machine Learning, Financial markets, and Geo-politics. He believes that he is competing against himself to become better than who he was yesterday. He aspires to become a well-recognized subject matter expert in the field of Artificial Intelligence.“

We are proud to stay that ZIFTM is currently the only AIOps platform in the market to have a native mobile version! Look for ZIFTM AIOps on the App Store and Google Play Store.

Please complete the form details and a customer success representative will reach out to you shortly to schedule the demo. Thanks for your interest in ZIF!
