
Lambda (λ), Kappa (κ) and Zeta (ζ) – The Tale of 3 AIOps Musketeers (PART-3)
“Data that sit unused are no different from data that were never collected in the first place.” – Doug Fisher
In the part 1 (https://bit.ly/3hDChCH), we delved into Lambda Architecture and in part 2 (https://bit.ly/3hDCg1B) about Generic Lambda. Given the limitations of the Generic lambda architecture and its inherent complexity, the data is replicated in two layers and keeping them in-sync is quite challenging in an already complex distributed system.There is a growing interest to find the simpler alternative to the Generic Lambda, that would bring just about the same benefits and handle the full problem set. The solution is Unified Lambda (λ) Architecture.
The unified approach addresses the velocity and volume problems of Big Data as it uses a hybrid computation model. This model combines both batch data and instantaneous data transparently.
There are basically three approaches:
In this approach, a pure streaming model is adopted and a flexible framework like Apache Samza can be employed to provide unified data processing model for both stream and batch processing using the same data flow structure.

To avoid the large turn-around times involved in Hadoop’s batch processing, LinkedIn came up with a distributed stream processing framework Apache Samza. It is built on top of distributed messaging bus; Apache Kafka, so that it can be a lightweight framework for streaming platform. i.e. for continuous data processing. Samza has built-in integration with Apache Kafka, which is comparable to HDFS and MapReduce. In the Hadoop world, HDFS is the storage layer and MapReduce, the processing layer. In the similar way, Apache Kafka ingests and stores the data in topics, which is then streamed and processed by Samza. Samza normally computes results continuously as and when the data arrives, thus delivering sub-second response times.
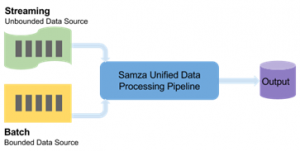
Albeit it’s a distributed stream processing framework, its architecture is pluggable i.e. can be integrated with umpteen sources like HDFS, Azure EventHubs, Kinensis etc. apart from Kafka. It follows the principle of WRITE ONCE, RUN ANYWHERE; meaning, the same code can run in both stream and batch mode. Apache Samza’s streams are re-playable, ordered partitions.
Apache Samza offers a unified data processing model for both real-time as well as batch processing. Based on the input data size, bounded or unbounded the data processing model can be identified, whether batch or stream.Typically bounded (e.g. static files on HDFS) are Batch data sources and streams are unbounded (e.g. a topic in Kafka). Under the bonnet, Apache Samza’s stream-processing engine handles both types with high efficiency.

Another advantage of this unified API for Batch and Streaming in Apache Samza, is that makes it convenient for the developers to focus on the processing logic, without treating bounded and unbounded sources differently. Samza differentiates the bounded and unboundeddata by a special token end-of-stream. Also, only config change is needed, and no code changes are required, in case of switching gears between batch and streaming, e.g. Kafka to HDFS.Let us take an example of Count PageViewEvent for each mobile Device OS in a 5-minute window and send the counts to PageViewEventPerDeviceOS

This is the reverse approach of pure streaming where a flexible Batch framework is employed, which would offer both the batch processing and real-time data processing ability. The streaming is achieved by using mini batches which is small enough to be close to real-time, with Apache Spark/Spark Streaming or Storm’s Trident. Under the hood, Spark streaming is a sequence of micro-batch processes with the sub-second latency. Trident is a high-level abstraction for doing streaming computation on top of Storm. The core data model of Trident is the “Stream”, processed as a series of batches.
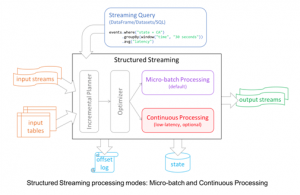
Apache Spark achieves the dual goal of Batch as well as real-time processing by the following modes.
Micro-batch processing model
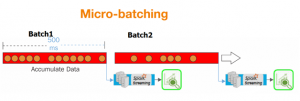
Micro-batch processing is analogous to the traditional batch processing in that data are usually processed as a group. The primary difference is that the batches are smaller and processed more often. In spark streaming, the micro-batches are created based on the time rather than on the accumulated data size. The smaller the time to trigger a micro-batch to process, lesser the latency.
Continuous Processing model
Apache Spark 2.3, introduced Low-latency Continuous Processing Mode in Structured Streaming whichenables low (~1 ms) end-to-end latency with at-least-once fault-tolerance guarantees. Comparing this with the default micro-batch processing engine which can achieve exactly-once guarantees but achieve latencies of ~100 ms at best. Without modifying the application logic i.e. DataFrame/Dataset operations mini-batching or continuous streaming can be chosen at runtime. Spark Streaming also has the abilityto work well with several data sources like HDFS, Flume or Kafka.
Example of Micro-batching and Continuous Batching


In many places, capability of both batch and real time processing is needed.It is cumbersome to develop a software architecture of such capabilities by tailoring suitable technologies, software layers, data sources, data storage solutions, smart algorithms and so on to achieve the good scalable solution. This is where the frameworks like Spring “XD”, Summingbird or Lambdoop comes in, since they already have a combined API for batch and real-time processing.
Lambdoop
Lambdoop is a software framework based on the Lambda architecture which provides an abstraction layer to the developers. This feature makes the developers life easy to develop any Big Data applications by combining real time and batch processing approaches. Developers don’t have to deal with different technologies, configurations, data formats etc. They can use the Lambdoop framework as the only needed API. Also, Lambdoop includes other interesting tools such as input/output drivers, visualization tools, cluster management tools and widely accepted AI algorithms.
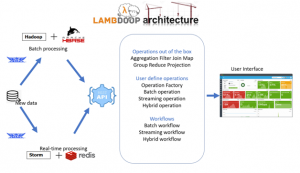
The Speed layer in Lambdoop runs on Storm and the Batch layer on Hadoop, Lambdoop (Lambda-Hadoop, with HBase, Storm and Redis) also combines batch/real-time by offering a single API for both processing models.
Summingbird
Summingbird aka‘Streaming MapReduce’ is a hybrid computational system where both the batch/streaming computations can be run at the same time and the results can be merged automatically. In Summingbird, the developer can write the code/job logic once and change the backend as and when needed. Following are the modes in which Summingbird Job/code can be executed.
If the model assumes streaming, one-at-a-time semantics, then the code can be run in real-time e.g. Strom or in offline/batch mode e.g. Hadoop, spark etc. It can operate in a hybrid processing mode, when there is a need to transparently integrate batch and online results to efficiently generate up-to-date views over long time spans.
Conclusion
The volume of any Big Data platform is handled by building a batch processing application which requires, MapReduce, spark development, Use of other Hadoop related tools like Sqoop, Zookeeper, HCatalog etc. and storage systems like HBase, MongoDB, HDFS, Cassandra. At the same time the velocity of any Big Data platform is handled by building a real-time streaming application which requires, stream computing development using Storm, Samza, Kafka-connect, Apache Flink andS4, and use of temporal datastores like in-memory data stores, Apache Kafka messaging system etc.
The Unified Lambda handles the both Volume and Velocity if any Big Data platform by the intermixed approach of featuring a hybrid computation model, where both batch and real-time data processing are combined transparently. Also, the limitations of Generic Lambda like Dual execution mode, Replicating and maintaining the data sync between different layers are avoided and in the Unified Lambda, there would be only one system to learn and maintain.

“ Bargunan is a Big Data Engineer and a programming enthusiast. His passion is to share his knowledge by writing his experiences about them. He believes “Gaining knowledge is the first step to wisdom and sharing it is the first step to humanity.“

We are proud to stay that ZIFTM is currently the only AIOps platform in the market to have a native mobile version! Look for ZIFTM AIOps on the App Store and Google Play Store.

Please complete the form details and a customer success representative will reach out to you shortly to schedule the demo. Thanks for your interest in ZIF!
