
Lambda (λ), Kappa (κ) and Zeta (ζ) – The tale of three musketeers (Part-2)
In my previous article https://bit.ly/2T7DO9r, we saw the brief introduction and terminologies of Lambda Architecture. Let’s jump on to its various implementation patterns in the enterprises.
Lambda data processing architecture can be implemented in three ways,
The three layers of Generic λ
The new information collected, or ingested data is sent simultaneously to both Batch and Speed/Streaming layers for processing. The batch layer, called ‘Data Lake’, handles two vital tasks.
1) Managing the master data set (Data Lake), which is an immutable append-only raw data.
2) Precomputing the batch views on business-relevant aggregations and metrics.
The computation from Batch Layer is fed into Serving Layer which indexes the batch views, for a low latency query.
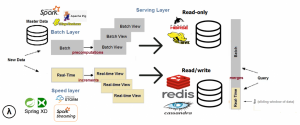
In the Speed layer or Streaming layer, the views are transient in nature, since only new data is considered to compensate for the high latency of the writes.
A serving layer can be a presentation side/reporting layer aimed to handle both batch reporting as well as real-time reporting. At the presentation side, queries are answered by merging both batch and real-time views.
The data pipeline can be broken down into layers with clear delineation of roles and responsibilities and at each layer, we can choose from several technologies. For instance, in the speed layer any of Apache Storm or Apache Spark Streaming, or spring ‘XD’ (eXtreme Data)could be employed.
The following table represents some of the Stream Processing Frameworks, that are well suited for the speed components.
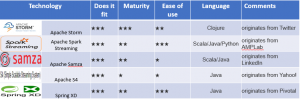
Apache Storm is an open-source, distributed, and advanced Big Data processing engine that processes the real-time streaming data at an unprecedented speed, way faster than Apache Hadoop. What Hadoop does for batch processing, Apache Storm does for unbounded streams of data in a reliable manner.
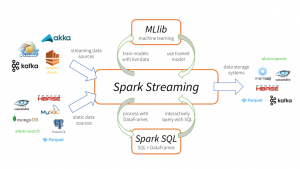
Spark Streaming was added to Apache Spark in 2013, an extension of the core Spark API that enables scalable, high-throughput, fault-tolerant stream processing of live data streams. Data is ingested from varied sources like Apache Kafka, Flume, Kinesis and can be processed using complex algorithms expressed with high-level functions like map, reduce, join, and window. The processed data can be pushed out to filesystems, databases, and live dashboards. Spark’s machine learning and graph processing algorithms can be applied to data streams.
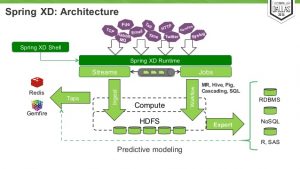
Spring XD (eXtreme Data) is a unified, distributed, and extensible service for data ingestion, real-time analytics, batch processing, and data export.
The Spring Data team has via Spring XD has provided support for NoSQL datastores and has also simplified the development experience with Hadoop. Spring XD is built on the fundamental blocks of Apache Hadoop. Also, it uses various pre-existing Spring technologies. For instance, Spring Data supports NoSQL/Hadoop work, Spring Batch is employed to support the workflow orchestration with job state management and retry/restart capabilities, and Spring Integration manages the event-driven data ingestion stream processing and the various Enterprise Application Integration patterns. Spring Reactor provides simplified API for developing asynchronous applications using the LMAX Disruptor.
Similarly, in Batch Layer frameworks like Apache Pig, Apache MapReduce and Apache spark can be employed. The Processing Frameworks that are commonly used in the batch layer are outlined below.
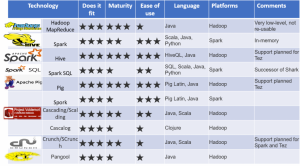
Hadoop MapReduce is a paradigm and software framework for writing applications that process large amounts of data on large clusters of commodity hardware in a parallel, reliable, fault-tolerant manner. MapReduce programs are written in various languages like Java, Ruby, Python, and C++ can be run in Apache Hadoop platform.
Apache Pig is an abstraction over MapReduce and a tool/platform for analyzing large data sets that consists of a high-level language for expressing data analysis programs, coupled with infrastructure for evaluating these programs. To address the problem of programs generating series of Map and Reduce stages in MapReduce, Apache Pig creates an abstraction over them. The most noticeable property of Pig programs is that their structure is amenable to substantial parallelization, which in turn enables them to handle very large data sets.
Apache Spark is the largest open source project in Big data processing. It is a blazing-fast cluster computing technology, designed for fast computation. It is based on Hadoop MapReduce and it extends the MapReduce model to efficiently use it for more types of computations, which includes interactive queries and stream processing. The main feature of Spark is its in-memory cluster computing that increases the processing speed of an application.
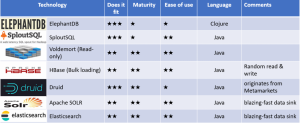
Technologies or Merge/Low-Latency Databases like Druid, Apache HBase, Elephant DB, Apache SOLR, Elasticsearch, Azure Cosmos DB, MongoDB, VoltDBcan be employed for speed-layer output.
In the generic lambda architecture, the data must be written twice i.e. data is sent to both the speed layer and the batch layer as it is created. Any logic is duplicated and implemented twice. The batch layer takes a while to produce results so the speed layer does the same work so it can answer questions about in-flight events and recent activities.
There are always two separate execution paths for streaming and batch. It’s a maintenance nightmare, where dealing with a plethora of frameworks, components, and clusters.
Typically, an undesirable effect of Generic Lambda is that the codebases tend to diverge since the code that executes in a batch world works on a large but finite data set while a real-time stream processing system works on an infinite event stream.
Just to manage the platform, more developers with diverse skill sets are needed than focusing on core business problems.
It is evident that the Generic Lambda λ fits best for the system that has fast data i.e. high velocity of data and Data Lake i.e. system that involves complex processing of both historical (re-computational) and real-time (incremental) aggregated view with nearly unlimited memory capacity and data storage space. Use cases like login gestion (syslog’s, application logs, weblogs), which are one-way data pipelines are some of the areas where the Generic Lambda λ shines the brightest. But having known the limitations of the Generic lambda λ, there is always a constant search to address its limitations. Let’s continue to explore to find solutions in the next part.
Happy Learning!

“Bargunan is a Big Data Engineer and a programming enthusiast. His passion is to share his knowledge by writing his experiences about them. He believes “Gaining knowledge is the first step to wisdom and sharing it is the first step to humanity.”“

We are proud to stay that ZIFTM is currently the only AIOps platform in the market to have a native mobile version! Look for ZIFTM AIOps on the App Store and Google Play Store.

Please complete the form details and a customer success representative will reach out to you shortly to schedule the demo. Thanks for your interest in ZIF!
