
Lambda (λ), Kappa (κ) and Zeta (ζ) – The Tale of 3 AIOps Musketeers (PART-1)
Architecture inspires people, no wonder so many famous writers, artists, politicians, and designers have such profound and fascinating observations about architecture. Whether embracing minimalism or adoring resplendence, everyone has experiences and tastes that shape the way they interact with the world. The Greek architectural beauties have captured the imagination of many. The crown jewel of their architecture is the “post and lintel” which was used for their grand, large, open-air structures that could accommodate 20,000 spectators.

Greeks are also famous for their Alphabets. When the Greek Architecture and Alphabets are merged, the state-of-the-art overarching “Big Data Processing Architecture” is produced; Lambda λ, kappa κ, and Zeta ζ.
The evolution of the technologies in Big Data in the last decade has presented a history of battles with growing data volume. An increasing number of systems are being built to handle the Volume, Velocity, Variety, Veracity, Validity, and Volatility of Big Data and help gain new insights and make better business decisions. A well-designed big data architecture must handle the 6 V’s of Big Data, save your company money, and help predict future trends.

The Lambda Architecture λis an emerging paradigm in Big Data computing. The name lambda architecture is derived from a functional point of view of data processingi.e. all data processing is understood as the application of a function to all data.
Lambda architecture is popular for its data processing technique of handling huge amounts of data by taking advantage of both a batch layer and a speed/stream-processing layer. This specific approach attempts to balance latency, throughput, and fault-tolerance by using batch processing to provide comprehensive and accurate views of batch data, while simultaneously using real-time stream processing to provide views of online data. The outputs from both batch and speed layers can be merged before the presentation.
The efficiency of this architecture becomes evident in the form of increased throughput, reduced latency, and negligible errors, thus resulting in a linearly scalable architecture that scales out rather than scaling up.
The Lambda Architecture achieves high scalability and low latency due to the following principles,
The Big Data immutability is based on similar principles as the immutability in programming data structures. The goal being the same – do not change the data in-place and instead create a new one. The data can’t be altered and deleted. This rule can be defined for eternity or for a specified time period.
Immutable data is fundamentally simpler than mutable data. The idea here is not to change the data in-place i.e. no updating or deleting of records but creating new ones. Now, this could be time-bound or for the eternity. Thus, write operations only add new data units. In CRUD parlance only CR (Create & Read) and no UD (Update & Delete).
This approach makes data handling highly scalable because it is very easy to distribute and replicate data. This immutable model makes the data aggregation kind of a logging system. With the attributes like “data creation timestamp”, the old and the most recent version can be distinguished. Apache Kafka – an append-only distributed log system is a great example of an immutable data store.
As a drawback, even more, data is generated, and answering queries becomes more difficult. For example, to find the current owner of a brand, the owner for that brand with the latest timestamp must be found.
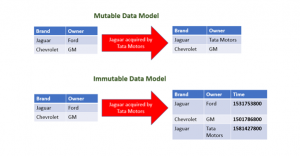
In the mutable data model, it is no longer possible to find out that the brand Jaguar was once owned by Ford. This is different when using an immutable data model which is achieved by adding a timestamp to each data record.
Now it is possible to get both bits of information: the fact that Jaguar is now owned by Tata Motors (latest timestamp) and the fact it was formerly owned by Ford. It is also much easier to recover from errors because the old information is not deleted.
The traditional database systems are named for their storage efficiency and data integrity. It is possible due to the Normalization process like 1NF, 2NF, 3NF, BCNF, 4NF, and 5NF. Due to efficient normalization strategy, data redundancy is eliminated. The same data need not be saved in multiple places (tables) and any updates (partial or full) on the same, need not be done at multiple places (tables). But this makes the traditional databases poor at scaling their read performance since data from multiple places (tables) need to be brought together by complex and costly join operations.
For the sake of performance, Big data systems accept denormalization and duplication of data as a fact of life with the data schema such that data stored in-representation is equivalent to that after performing joins on normalized tables.

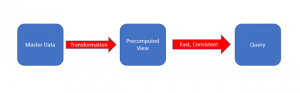
In this way, the knowledge about the schema is not necessary, and joins can be avoided, and the query results are faster. This also motivates the query-driven data modeling methodology. Albeit the data exists in multiple places after denormalization, the consistency of the data is ensured via strong consistency, timeline consistency, and eventual consistency models in the event of partial or full updates. This is often acceptable, especially when denormalized representations are used as precomputed views.
To give fast and consistent answers to queries on huge amounts of data, precomputed views are prepared both in the batch layer and in the speed layer. In the batch layer, these are constructed by applying a batch function to all the data. This leads to a transformation of the data into a more compact form suitable for answering a pre-defined set of queries. This idea is essentially the same as what is done in data warehousing.
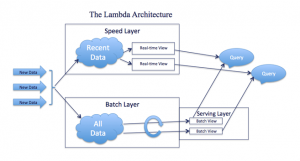
The Lambda Architecture solves the problem of computing arbitrary functions on arbitrary data in real-time by decomposing the problem into three layers,
The nub of the λ is the master dataset. The master dataset is the source of truth in Lambda Architecture. The Master dataset must hold the following three properties,
This gives the Lambda architecture ability to reconstruct the application from the master data even if the whole serving layer data set is lost. The batch layer pre-computes results using a distributed processing system that can handle very large quantities of data. The batch layer aims at perfect accuracy by being able to process all available data when generating views.
The batch layer prefers re-computation algorithms over incremental algorithms. The problem with incremental algorithms is the failure to address the challenges faced by human mistakes. The re-computational nature of the batch layer creates simple batch views as the complexity is addressed during precomputation. Additionally, the responsibility of the batch layer is to historically process the data with high accuracy. Machine learning algorithms take time to train the model and give better results over time. Such naturally exhaustive and time-consuming tasks are processed inside the batch layer.

The problem with the batch layer is high latency. The batch jobs must be run over the entire master dataset. These jobs can process data that can be relatively old as they cannot keep up with the inflow of stream data. This is a serious limitation for real-time data processing. To overcome this limitation, the speed layer is very significant.
Frameworks and solutions such as Hadoop MapReduce, Spark core, Spark SQL, GraphX, and MLLib are the widely adopted big-data tools using batch mode. Batch schedulers include Apache Oozie, Spring Batch, and Unix crontab which, invoke the processing at a periodic interval.
The real-time data processing is realized in the speed layer. The speed layer achieves up-to-date query results and compensates for the high latency of the batch layer.
To create real-time views of the most recent data, this layer sacrifices throughput and decreases latency substantially. The real-time views are generated immediately after the data is received but are not as complete or precise as the batch layer. In contrast to the re-computation approach of the batch layer, the speed layer adopts incremental computational algorithms. Since the data is not complete i.e less data so less computation. The incremental computation is more complex, but the data handled in the speed layer is vastly smaller and the views are transient.
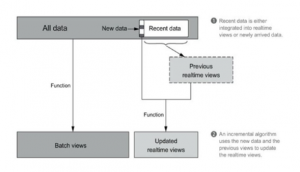
Most operations on streams are windowed operations operating on slices of time such as moving averages for the stock process every hour, top products sold this week, fraud attempts in banking, etc. Popular choices for stream-processing tools include Apache Kafka, Apache Flume, Apache Storm, Spark Streaming, Apache Flink, Amazon Kinesis, etc.
The output from both the batch and speed layers are stored in the serving layer.pre-computed batch views are indexed in this layer for faster retrieval. All the on-demand queries from the reporting or presentation layer are served by merging the batch and real-time views and outputs a result.
Query = λ (Complete data) = λ (live streaming data) * λ (Stored data)
The must-haves of the serving layer are,
The batch views for a serving layer are produced from scratch. When a new version of a view becomes available, it must be possible to completely swap out the older version with the updated view.
A serving layer database must be capable of handling views of arbitrary size. As with the distributed filesystems and batch computation framework previously discussed, this requires it to be distributed across multiple machines.
A serving layer database must support random reads, with indexes providing direct access to small portions of the view. This requirement is necessary to have low latency on queries.
Because a serving layer database is distributed, it must be tolerant of machine failures.
This is how Lambda Architecture λ handles humongous amounts of data with low latency queries in a fault-tolerant manner. Let’s see the various implementation of lambda architecture and its applications in the next part.
To be continued…

“ Bargunan is a Big Data Engineer and a programming enthusiast. His passion is to share his knowledge by writing his experiences about them. He believes “Gaining knowledge is the first step to wisdom and sharing it is the first step to humanity.“

We are proud to stay that ZIFTM is currently the only AIOps platform in the market to have a native mobile version! Look for ZIFTM AIOps on the App Store and Google Play Store.

Please complete the form details and a customer success representative will reach out to you shortly to schedule the demo. Thanks for your interest in ZIF!
