
Inverse Reinforcement Learning
Inverse reinforcement learning is a recently developed Machine Learning framework that can solve the inverse problem of Reinforcement Learning (RL). Basically, IRL is about learning from humans. Inverse reinforcement learning is the field of learning an agent’s objectives, values, or rewards by observing its behavior.
Before getting into further details of IRL, let us recap RL.
Reinforcement learning is an area of Machine Learning (ML) that takes suitable actions to maximize rewards. The goal of reinforcement learning algorithms is to find the best possible action to take in a specific situation.
One of the hardest challenges in many reinforcement learning tasks is that it is often difficult to find a good reward function which is both learnable (i.e. rewards happen early and often enough) and correct (i.e. leads to the desired outcomes). Inverse reinforcement learning aims to deal with this problem by learning a reward function based on observations of expert behavior.
In RL, our agent is provided with a reward function which, whenever it executes an action in some state, provides feedback about the agent’s performance. This reward function is used to obtain an optimal policy, one where the expected future reward (discounted by how far away it will occur) is maximal.
In IRL, the setting is (as the name suggests) inverse. We are now given some agent’s policy or a history of behavior and we try to find a reward function that explains the given behavior. Under the assumption that our agent acted optimally, i.e. always picks the best possible action for its reward function, we try to estimate a reward function that could have led to this behavior.
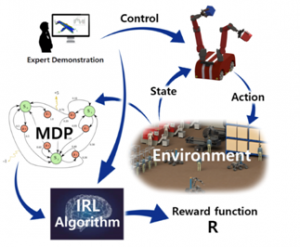
Maybe the biggest motivation for IRL is that it is often immensely difficult to manually specify a reward function for a task. So far, RL has been successfully applied in domains where the reward function is very clear. But in the real world, it is often not clear at all what the reward should be and there are rarely intrinsic reward signals such as a game score.
For example, consider we want to design an artificial intelligence for a self-driving car. A simple approach would be to create a reward function that captures the desired behavior of a driver, like stopping at red lights, staying off the sidewalk, avoiding pedestrians, and so on. In real life, this would require an exhaustive list of every behavior we’d want to consider, as well as a list of weights describing how important each behavior is.
Instead, in the IRL framework, the task is to take a set of human-generated driving data and extract an approximation of that human’s reward function for the task. Of course, this approximation necessarily deals with a simplified model of driving. Still, much of the information necessary for solving a problem is captured within the approximation of the true reward function. Since it quantifies how good or bad certain actions are. Once we have the right reward function, the problem is reduced to finding the right policy and can be solved with standard reinforcement learning methods.
For our self-driving car example, we’d be using human driving data to automatically learn the right feature weights for the reward. Since the task is described completely by the reward function, we do not even need to know the specifics of the human policy, so long as we have the right reward function to optimize. In the general case, algorithms that solve the IRL problem can be seen as a method for leveraging expert knowledge to convert a task description into a compact reward function.
The foundational methods of inverse reinforcement learning can achieve their results by leveraging information obtained from a policy executed by a human expert. However, in the long run, the goal is for machine learning systems to learn from a wide range of human data and perform tasks that are beyond the abilities of human experts.

“ Naresh is a part of Location Zero at GAVS as an AI/ML solutions developer. His focus is on solving problems leveraging AI/ML. He strongly believes in making success as an habit rather than considering it a destination. In his free time, he likes to spend time with his pet dogs and likes sketching and gardening.“

We are proud to stay that ZIFTM is currently the only AIOps platform in the market to have a native mobile version! Look for ZIFTM AIOps on the App Store and Google Play Store.

Please complete the form details and a customer success representative will reach out to you shortly to schedule the demo. Thanks for your interest in ZIF!

{kind=link}